What is parallel processing?

Parallel processing is a method in computing of running two or more processors, or CPUs, to handle separate parts of an overall task. Breaking up different parts of a task among multiple processors helps reduce the amount of time it takes to run a program. Any system that has more than one CPU can perform parallel processing, as well as multicore processors, which are commonly found on computers today.
Multicore processors are integrated circuit chips that contain two or more processors for better performance, reduced power consumption and more efficient processing of multiple tasks. These multicore setups are like having multiple separate processors installed in the same computer. Most computers have anywhere from two cores up to 12 cores.
Parallel processing is commonly used to perform complex tasks and computations. Data scientists commonly use parallel processing for setups and data-intensive tasks.
How parallel processing works
Parallel processing divides a task between two or more microprocessors. Typically, a complex task is divided into multiple parts using a specialized software tool that assigns each part to a processor based on the task's component elements. Larger tasks are broken into multiple smaller parts that are appropriate for the number, type and size of available processing units. Then, each processor completes its part, and the software tool reassembles the data and executes the task.
Typically, each processor operates normally and performs operations in parallel as instructed, pulling data from the computer's memory. Processors also rely on software to communicate with each other so they can stay in sync concerning changes in data values. Assuming all the processors remain in sync with one another, at the end of a task, the software fits all the data pieces together.
Parallel processes are either fine-grained or coarse-grained. In fine-grained parallel processing, tasks communicate with one another multiple times. This is suitable for processes that require real-time data. Coarse-grained parallel processing, on the other hand, deals with larger pieces of a task and requires less frequent communication between processors. This type of processing is more useful in applications that have tasks with minimal interdependencies and can be naturally divided into larger parts.
Computers without multiple processors can also still be used in parallel processing if they're networked together to form a cluster.
Types of parallel processing
There are multiple types of parallel processing, including the following:
- Single instruction multiple data (SIMD). A computer has two or more processors that follow the same instruction set while each processor handles different data. SIMD is commonly used to analyze large data sets that are based on the same specified benchmarks.
- Multiple instruction multiple data (MIMD). In this commonly used type of parallel processing, each computer has two or more of its own processors and gets data from separate data streams.
- Multiple instruction single data (MISD). Each processor uses different instructions with the same input data simultaneously. This type of processing is used less frequently.
- Single program multiple data (SPMD). Multiple processors execute the same task but take on different data sets. This type of processing is typically used for simulations, data processing or parallel algorithms.
- Massively parallel processing. MPP uses many processors to perform coordinated tasks in parallel. These systems use up to hundreds or thousands of processors that are all independently handling a portion of an overall task. This type of processing is used to solve large and complex problems that wouldn't be possible with fewer processors.
Difference between serial and parallel processing
Parallel processing can complete multiple tasks using two or more processors whereas serial processing -- also called sequential processing -- only completes one task at a time using one processor. If a computer needs to complete multiple assigned tasks, it will complete one task at a time. Likewise, if a computer using serial processing needs to complete a complex task, it will take longer compared to a parallel processor.
History of parallel processing
In the earliest computers, only one program ran at a time. It would take a total of two hours to run both a computation-intensive program that would take one hour to run and a tape copying program that took one hour to run. An early form of parallel processing enabled the interleaved execution of both programs together. The computer would start an input/output (I/O) operation, and while it was waiting for the operation to complete, it would execute the processor-intensive program. The total execution time for the two jobs was a little over one hour.
The next improvement was multiprogramming in the late 1950s and early 1960s. In a multiprogramming system, multiple programs submitted by users were each allowed to use the processor for a short time. To users, it appeared that all the programs were executing at the same time. Problems of resource contention first arose in these systems. Explicit requests for resources led to the problem of deadlock, where simultaneous requests for resources would effectively prevent a program from accessing the resource. Competition for resources on machines with no tie-breaking instructions led to the critical section routine.
Vector processing was another attempt, starting in 1964, to increase performance by doing more than one thing at a time. In this case, capabilities were added to machines to allow a single instruction to add or subtract, multiply or otherwise manipulate two arrays of numbers. This was valuable in certain engineering applications where data naturally occurred in the form of vectors or matrices. In applications with less well-formed data, vector processing wasn't as valuable.
The next step in parallel processing was the introduction of multiprocessing in the 1970s. In these systems, two or more processors shared the work to be done. The earliest versions had a primary and secondary configuration. The primary processor was programmed to be responsible for all the work in the system; the secondary processor performed only those tasks it was assigned by the primary processor. This arrangement was necessary because it wasn't then understood how to program the machines so they could cooperate in managing the resources of the system. Multiprocessing continued to improve into the 1980s, 1990s and beyond.
The early 2000s saw the development of distributed computing, often involving multiple independent computers that could work on a task together, without shared memory.
The early 2000s and onwards also saw an increase in the use of graphics processing units (GPUs), which consist of a large number of smaller processing units, called cores. Each core can execute its instructions independently of the others, which enables parallel processing. GPUs are also increasingly used for general-purpose computing tasks -- beyond just graphics.
Since then, there have been developments such as specialized hardware accelerators, which include field-programmable gate arrays and application-specific integrated circuits that speed up processing for specific parallel processing tasks.
Most recently, organizations have started to implement quantum computers that focus on creating quantum parallel processors that perform computations with qubits.
SMP and MPP
Symmetric multiprocessing (SMP) and MPP are both methods of parallel processing that are commonly compared to one another.
- SMP. Multiple processors share a common operating system (OS) and memory. The processors share the same I/O bus or data path and a single copy of the OS oversees all the processors.
- MPP. This coordinated processing technique uses many processors that work on different parts of a task, with each processor using its own OS and memory. Typically, MPP processors communicate using some messaging interface.
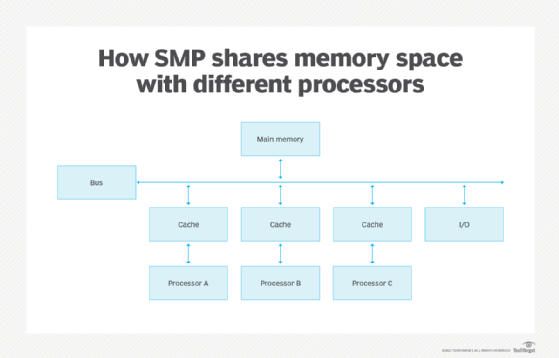
In an SMP system, each processor is equally capable and responsible for managing the flow of work through the system. Initially, the goal was to make SMP systems appear to programmers to be exactly the same as a single processor, multiprogramming system. However, engineers found that system performance could be increased by 10%-20% by executing some instructions out of order and requiring programmers to deal with the increased complexity. This meant the problem only became visible when two or more programs simultaneously read and wrote the same operands; thus the burden of dealing with the increased complexity would fall on only a few programmers and then only in specialized circumstances.
As the number of processors in SMP systems increases, the time it takes for data to propagate from one part of the system to all other parts also increases. When the number of processors is somewhere in the range of several dozen, the performance benefit of adding more processors to the system is too small to justify the additional expense. To get around the problem of long propagation times, a message passing system was created. In these systems, programs that share data send messages to each other to announce that particular operands have been assigned a new value. Instead of a broadcast of an operand's new value to all parts of a system, the new value is communicated only to those programs that need to know the new value. Instead of shared memory, there's a network to support the transfer of messages between programs. This simplification allows hundreds, even thousands, of processors to work together efficiently in one system. Hence, such systems have been given the name of massively parallel processing systems.
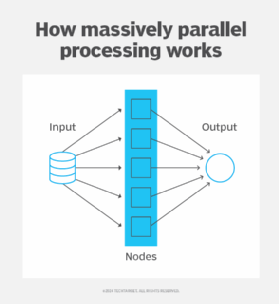
The most successful MPP applications have been for problems that can be broken down into many separate, independent operations on vast quantities of data. In data mining, there's a need to perform multiple searches of a static database. In artificial intelligence, there's a need to analyze multiple alternatives, as in a chess game. Often, MPP systems are structured as clusters of processors. Within each cluster, the processors interact as if they were an SMP system. It's only between the clusters that messages are passed. Because operands can be addressed either via messages or memory addresses, some MPP systems are called NUMA machines, for nonuniform memory addressing.
SMP machines are relatively simple to program; MPP machines are not. SMP machines do well on all types of problems, providing the amount of data involved isn't too large. However, for certain problems, such as data mining of massive databases, only MPP systems are feasible.
Modern CPUs and GPUs can both run AI workloads in parallel. Learn how the two compare for this use case.







